What makes system reliable
- Not about preventing all failures, but being able to work correctly when failures happen
CAP Theorem
- Establishes a fundamental constraint

- Distributed systems can only provide 2 at most of these 3
Consistency
- All nodes see the same data at the same time
Availability
- Every request to a non-failing node receives a response
Partition Tolerance
- System continues to operate despite network failures
Since network partitions are unavoidable in distributed systems, we end up having to choose between consistency and availability during partition events
- EG Google Spanner chooses consistency, using atomic clocks to synchronise time across global data centres to maintain linearisable transactions
- Majority partitions remain read and write, while minority become read only
- Trade off: minority lose write access
- EG Amazons Dynamo DB chooses availability: it uses eventual consistency, allowing writes during network partitions, resolving conflicts based on last write wins based on timestamps
- Trade off: Occasionally get stale data
Eventual Consistency
- A promise that is: if we stop making updates, all replicas will eventually converge to the same state
- Powerful for large scale systems
- Allows writes to complete immediately without waiting for confirmation from all replicas, improves performance and availability
- EG Amazon: allows user to add items even if some servers will temporarily unreachable
How handle conflicts
- Last write wins use the most recent timestamp to pick the most recent update
- Simple, but can lose data
- Conflict free replicated data types use mathematical properties to guarantee all replicas converge to the same state regardless of update order
- Custom logic to resolve conflicts based on business rules Dynamo DB typically achieve consistency within milliseconds under normal conditions, making eventual consistency barely noticeable
Load balancing
- Distribute requests across multiple servers
Types of effective load balancing
- Layer 4 load balancer
- Operate on the transport layer
- Make routing decisions based on IP addresses and TCP/UDP ports
- Fast because do not need to inspect application data
- Limited in routing intelligence
- Layer 7 load balancer
- Operates on the application layer
- Can examine HTTP headers, URLs and request content to make smarter routing decisions
- More computationally expensive
- Least connections
- Sends requests to the server handling fewest active connections
- Least time
- Factors how quickly each server responds, avoiding slower servers
Consistent hashing
- Ensure the same client consistently hits the same server, critical for maintaining session state
Problems with horizontally scaled systems
- Data is spread across multiple nodes, and we need to add or remove nodes without moving massive amounts of data
- Traditional hashing does not work, adding 1 node requires remapping for almost all data
- Expensive and disruptive
How consistent hashing solves this
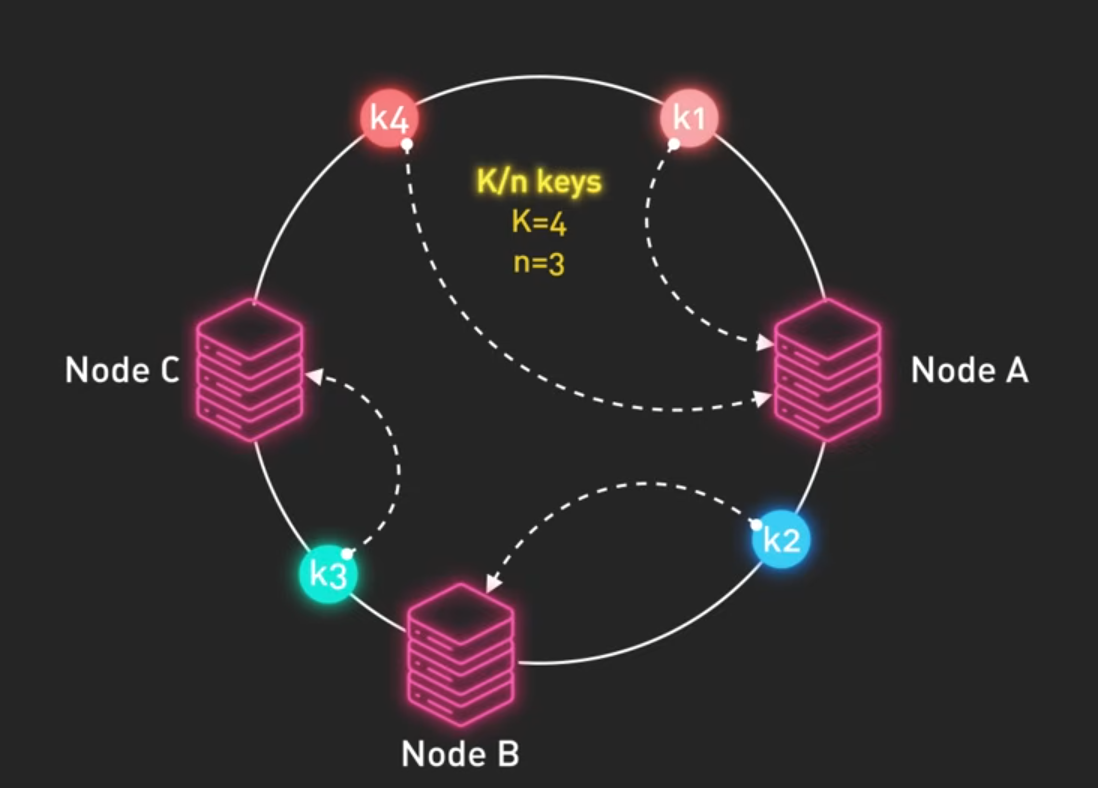
- Instead of mapping keys to nodes, both are placed on a circular hash ring
- Used by Amazon Dynamo DB and Apache Cassandra, allowing efficient horizontal scaling
- Hash each node to determine its position on the ring
- To find where data belong, hash the key and walk clockwise around the ring until we hit the first node
- Replicate the data to the next n-1 node clockwise on the ring
- When new node is added, it takes ownership from its immediate neighbours
- When a node is removed, its keys get redistributed to the next node on the ring
- Only requires moving K/n keys instead of nearly all keys (k=keys, n=node)
Circuit breakers
- Prevents failures across dependent services when 1 service in a distributed service fails
- Monitors failure rate of calls to the dependent services
Three states
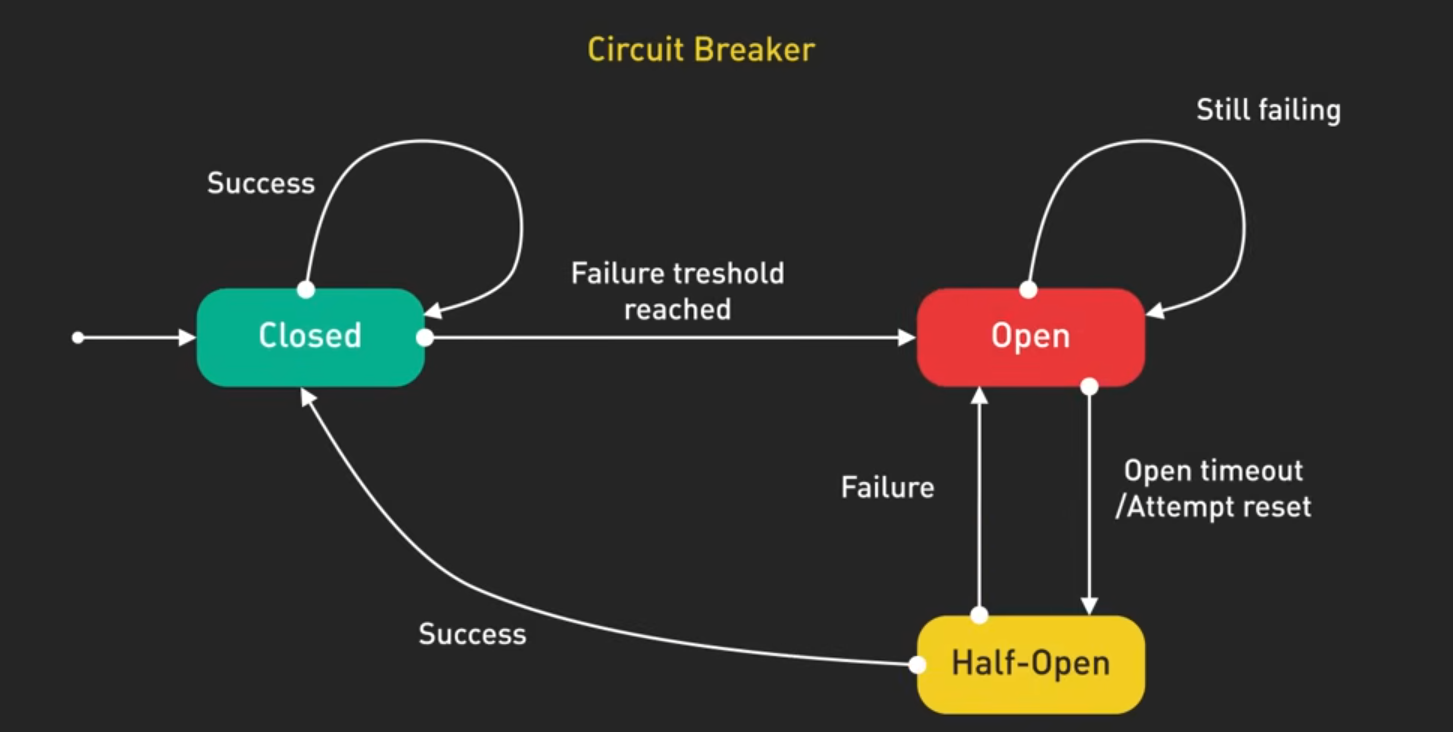
- Closed: requests flow normally
- Open: requests are blocked immediately without attempting to call the failing service, returning fast failures
- Half open: a few test requests allowed through to check if the service has recovered
How it works
- Circuit breaker checks successful and failed requests to a service
- When the failure rate exceeds threshold, circuit breaker trips to open state
- Prevents resource exhaustion and gives the service time to recover
- After a timeout period, circuit breaker moves to half open and allow a few test requests through
- If the test requests succeed, the circuit breaker closes again and normal operation resumes
Origin
- Pioneered by Netflix’s Hystrix library
- Now standard in microservice architecture
Rate limiting
- Controls how many requests a client can make during a given time window
- Protects systems from overload and abuse
Algorithms to rate limit
- Token bucket algorithm
- Accumulate tokens at a fixed rate, up to a maximum capacity
- Each request consumes a token
- Allows control burst while maintaining an average rate
- Leaky bucket
- Processes requests at a constant rate, smoothing out traffic spikes
- Excess requests are queued or dropped
- Fixed window
- Counts requests in discrete time intervals
- Simple but prone to boundary effects such as clients doubling the rate by timing requests around the window boundaries
- Sliding window
- Uses a rolling average that smooths out problems of fixed windows
Rate limiting in distributed systems
- More complex, cannot just count requests in a single server, needs coordination across multiple instances
- One solution is Redis rate limiter to allow consistent rate limiting across the service cluster
Tier-rate limiting
- Different limits for authenticated vs anonymous users
- Progressive stricter limits as suspicious patterns are detected
Monitoring
- Provides visibility into system behaviour and performance
- Large scale system generates terabytes of monitoring data daily
- Static thresholds work for stable metrics, but fail when traffic patterns change
- Modern system uses statistical anomaly detection that learns normal patterns and alerts on deviation (ML models)
- Composite alerts combine multiple signals to reduce noise, such as alerting when CPU is high and error rates are increasing and response time is slow
4 key signal types:
- Metrics
- Time series
- Numerical data: CPU usage, request rate, error count
- Logs
- Structured records of discrete events with contextual information
- Traces
- End to end request flows, showing how a single request move through the distributed system
- Events
- Significant occurrences like deployment or config changes
Effective alerting
- Balances 2 concerns: catch problems quickly, but not get overwhelmed by false alarms